放大资金,增加盈利可能
配资是一种为投资者提供杠杆资金的金融服务!

配资是一种为投资者提供杠杆资金的金融服务!

在AI技术深度融入设备生态的当下,GTi15 Ultra凭借本地AI大模型部署与特色语音交互功能,成为硬件产品AI的焦点。本次评测围绕其AI算力、本地大模型体验、语音交互等维度展开,探究设备在实际场景中的AI应用实力。

▲GTi15 Ultra 可以作为一款专注于本地AI大模型和语音交互的高性能设备。配备99 TOPS的AI算力,与上一代 34.5 TOPS相比,算力提升达187%,在本地推理任务中展现出惊人的效率和稳定性。无论是复杂的模型训练还是大规模推理任务,GTi15 Ultra都能轻松应对,大幅缩短推理时间,为用户带来更高效的AI体验。
本地大模型体验:开源模型的本地适配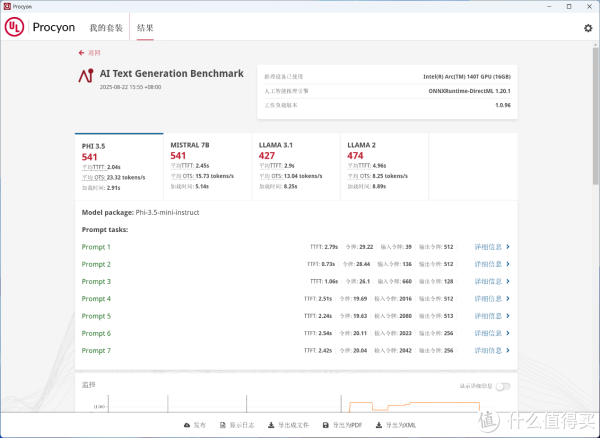
▲AI Text Generation Benchmark使用ONNXRuntime-DirectML 1.20.1人工智能推理引擎, LLAMA-3.1-8B得分427,MISTRAL-7B得分541,PHI-3.5-mini得分541,LLAMA-2-13B得分474。
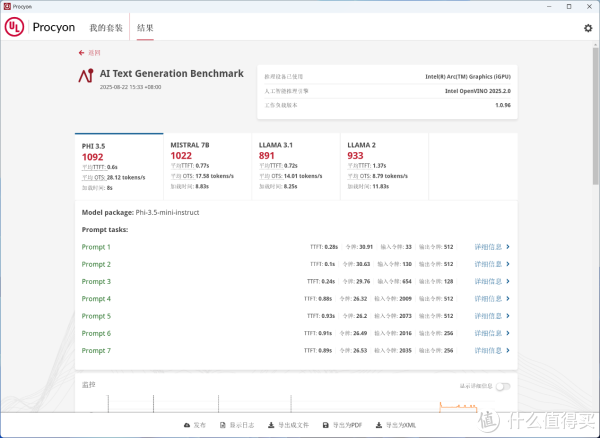
▲AI Text Generation Benchmark使用Intel OpenVINO 2025.2.0人工智能推理引擎,LLAMA-3.1-8B得分891,MISTRAL-7B得分1022,PHI-3.5-mini得分1092,LLAMA-2-13B得分933。
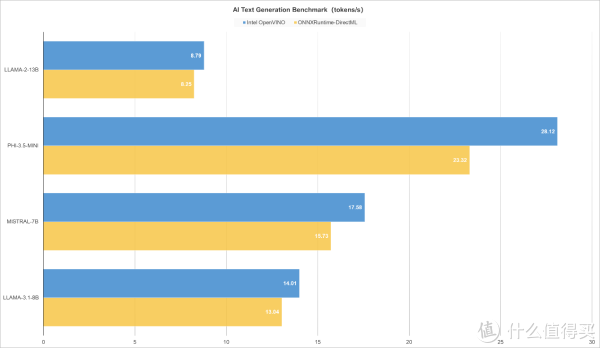
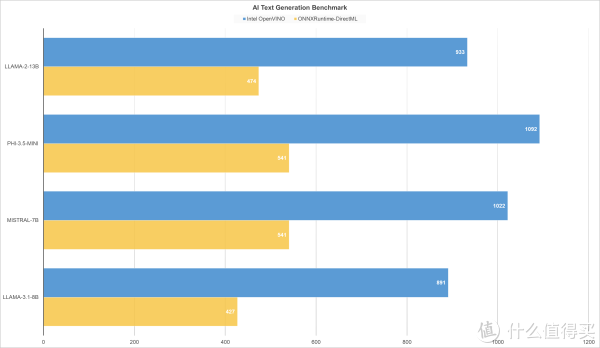
▲Intel锐炫140T核显搭配 Intel OpenVINO 推理引擎,在AI文本生成模型测试里,性能表现更优,文本生成速度更快;以MISTRAL-7B为例,Intel锐炫140T在处理具有70亿参数的模型时,能够提供更高的推理效率和较好的文本生成质量,更适合需要适中显存和算力的场景,如短文本生成、对话系统等。

▲实际应用中,我们使用LM Studio本地部署一个Deepseek R1 qwen3 8b模型,让模型为一个18个月的宝宝安排一天的作息,回答生成速度12.35 token/s。
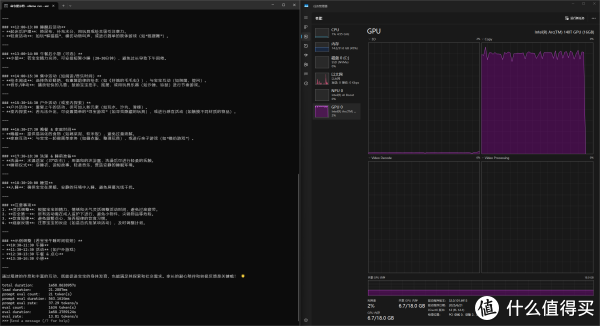
▲继续使用Ollama本地部署一个qwen3:8b模型,让模型为一个18个月的宝宝安排一天的作息,回答生成速度13.81 token/s。内存总占用在14.2GB,显存占用6.7GB。
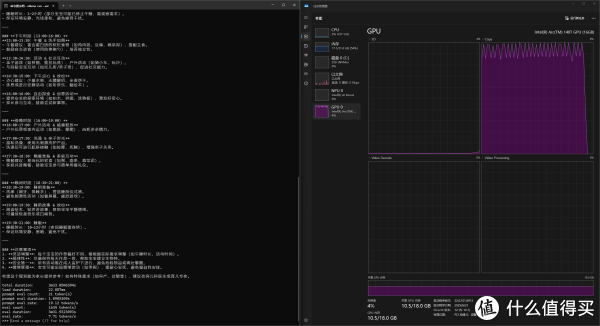
▲使用Ollama本地部署一个qwen3:14b模型,让模型为一个18个月的宝宝安排一天的作息,回答生成速度7.71 token/s。内存总占用在17.1GB,显存占用10.5GB。由于显存和内存公用,且显存最大只支持18GB,部署本地大模型时要注意内存占用。
从实际部署案例来看,8B参数级别的模型在Gti15 Ultra上表现最优。硬件资源消耗适中,既保证生成效率,又不会导致系统卡顿,完全能应对短文本创作、生活建议、知识问答等日常轻量化场景。
AI赋能生产力:Stable Diffusion本地图像生成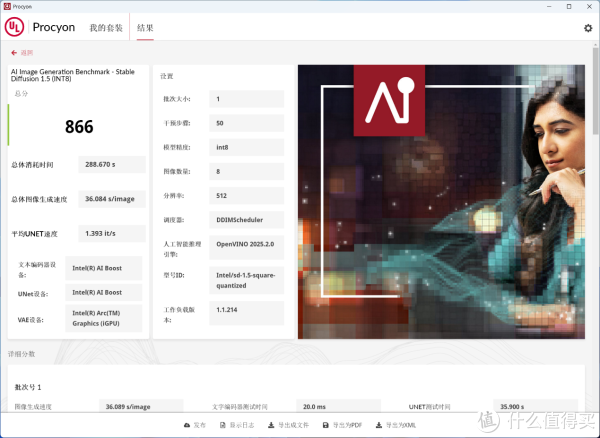
▲AI Image Generation Benchmark, 针对 Stable Diffusion 1.5(INT8 量化版本)模型,处理8张512分辨率图像,采用 NPU推理加速进行测试。使用NPU推理得分866,图像生成时间为288.670s。
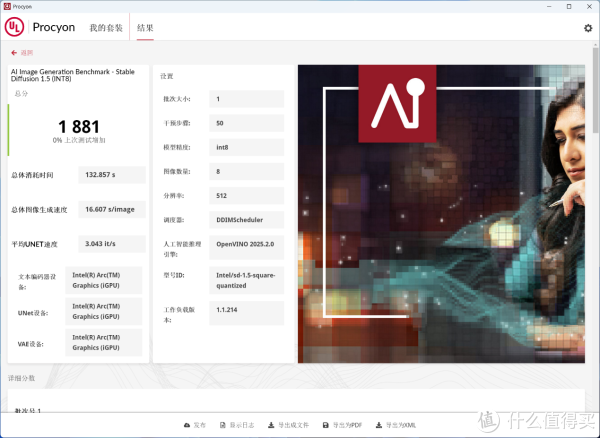
▲AI Image Generation Benchmark,针对 Stable Diffusion 1.5(INT8 量化版本)模型,处理 8张512分辨率图像,采用 GPU推理加速进行测试。使用GPU推理得分1881,图像生成时间为132.857s。
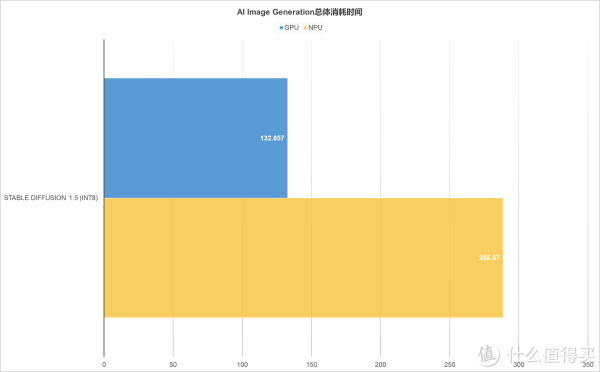
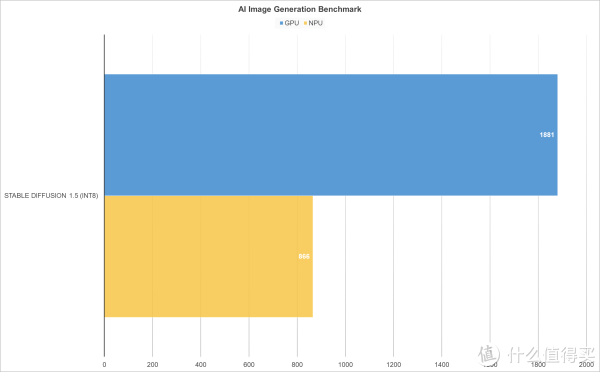
▲虽然Intel的NPU在AI图像生成方面能够提供一定的算力支持, 但与GPU相比,无论是在生成速度还是综合性能得分上都存在一定差距。GPU为图形渲染与并行计算设计,擅长处理大规模矩阵运算,正契合AI图像生成的算力需求。而NPU专为深度学习任务优化,低功耗是其亮点,在轻量化AI应用、智能物联网设备中发展空间广阔。但在需海量并行计算的图像生成任务中,算力受限导致速度与综合性能一般。
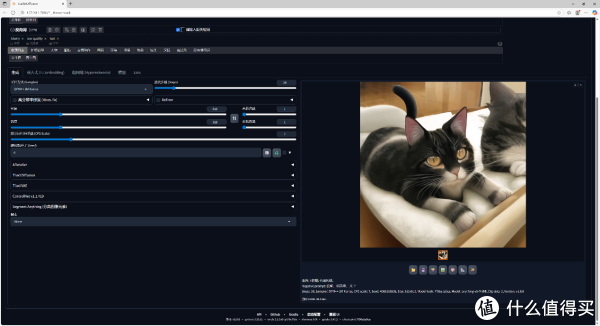
▲实际应用中,我们使用绘世2.8.13进行Stable Diffusion文生图测试,设置2个正向关键词精准描述画面元素,搭配3个反向词规避低质效果,迭代步数设为20,画面分辨率固定 512*512。实测生成一只猫咪图像,耗时约 6分45秒。因依赖CPU引擎运算,生成效率受硬件限制明显。
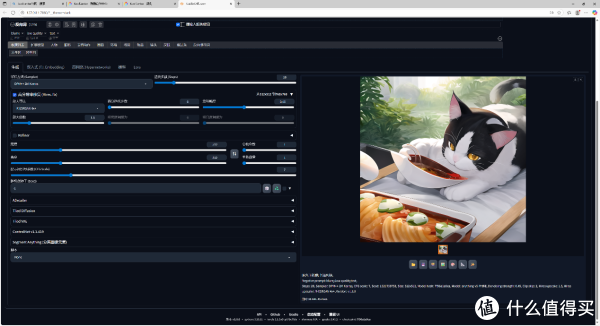
▲在基础测试参数(关键词、迭代步数等)不变前提下,开启高分辨率修复功能:选用 R - ESRGAN 4x+ 放大算法,设置放大倍数1.5 ,对原始图像进行细节强化与分辨率提升。生成画面因算法叠加、运算量倍增,实测耗时达33分45秒 ,CPU算力瓶颈进一步凸显。
当前绘世 2.8.13 版本在 Stable Diffusion 文生图流程中,暂不支持PyTorch XPU设备为Intel锐炫140T GPU引擎加速 ,只能调用CPU运算,导致生成时间显著延长。若后续版本优化硬件适配,借助GPU并行计算优势,有望大幅压缩文生图及修复流程的耗时,提升创作效率。
豆包 AI 语音交互:嘈杂环境的精准拾音零刻 GTi15 Ultra 的麦克风阵列与智能降噪芯片在语音交互方面表现十分出色,支持主流AI大模型(如AI豆包),能智能识别人声与噪音声纹频谱,无障碍识别语音指令
麦克风阵列:零刻 GTi15 Ultra 的正面上方有 4 颗等间距的麦克风阵列开孔,组成了 AI 阵列降噪麦克风。这种设计使得麦克风能够 360° 全方位收音,确保在各种场景下都能有效拾取声音。
智能降噪芯片:麦克风阵列内置了 MIC 智能拾音降噪B1 AI芯片,该芯片为麦克风的高效工作和出色的降噪效果提供了有力支持。

▲在环境噪音高达64.4dB的复杂场景中,我们针对豆包AI的人声语音识别能力展开了一场严苛测试。窗外工程车辆的持续轰鸣声构成了显著的背景噪音干扰。然而,在这样的声学挑战下,凭借Gti15 Ultra内置的B1 AI芯片,依然实现了对人声语音的精准捕捉与识别,语音识别准确率稳定在100%。
这一测试结果充分彰显了B1 AI芯片在复杂声学环境下的强大性能,它能够高效筛选出目标语音信号,过滤掉干扰噪音,确保语音信息的准确获取,为用户提供进一步的语音交互体验。
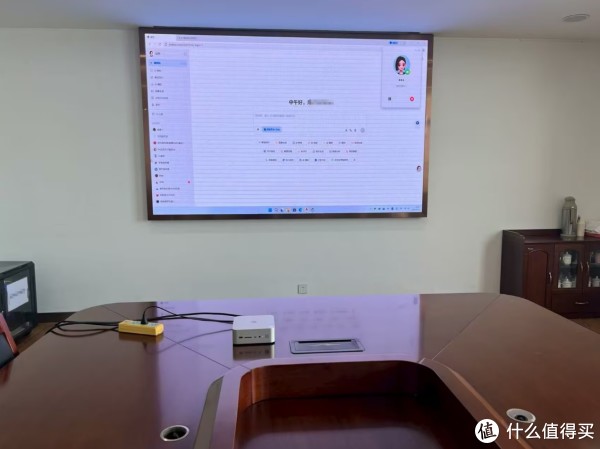
▲AI辅助办公的会议室场景中,零刻GTi15 Ultra与豆包AI协同,成为高效会议记录的 “黄金搭档” 。当多人围坐讨论,七嘴八舌、观点交织时,GTi15 Ultra 也能凭借出色麦克风阵列,如 “听力” 过人的助手,精准捕捉每一句发言,清晰识别、准确转写。配合豆包AI快速梳理,繁杂讨论秒变条理清晰的会议纪要,让思路高效落地,尽显科技赋能办公的便捷,重塑会议记录体验。
此外,GTi15 Ultra的应用场景远不止会议室。在对语音识别和文字转化有高要求的领域,如法庭速录,它同样表现出色。其精准拾音和高效转写能力,可显著提升速录员的工作效率,减少人工输入错误,为司法工作等专业场景提供有力支持。随着技术的不断发展,GTi15 Ultra 未来有望在更多领域取代传统速录方式,引领办公智能化的新潮流。
网络升级助力:万兆网口的协同效能
▲本次测试聚焦GTi15 Ultra在万兆网络环境下的性能表现,搭建专属测试架构:以GTi15 Ultra为核心终端,通过10Gbps LAN网口,连接网件MS510TXUP交换机,再由交换机引出10Gbps LAN链路对接群晖DS1821+,构建起万兆局域网测试环境。
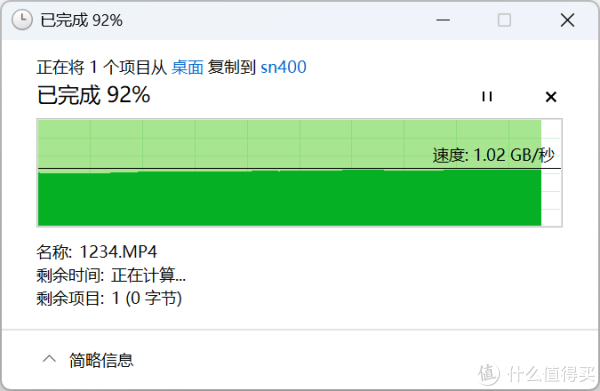
▲从Gti15 Ultra向DS1821+上传文件,写入速率为1.02GB/s。
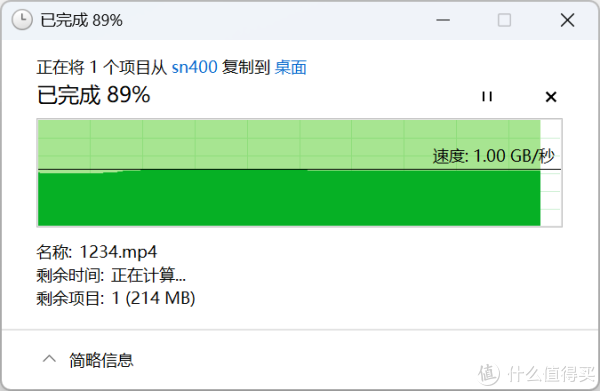
▲从Gti15 Ultra向DS1821+取回文件,读取速率为1.00GB/s。

▲在万兆局域网的加持下,我们能够更加专注地完成在线素材剪辑工作。GTi15 Ultra通过10G高速网络无缝调取 DS1821 +存储设备中的海量素材。
在 Adobe Premiere Pro 2025 软件中,GTi15 Ultra 凭借其强大的本地AI算力与GPU加速能力,可以实现1080P多轨道素材的实时预览与流畅剪辑。即便面对时间线拖动、特效实时计算等高负载任务,也能保持帧级同步,确保剪辑过程稳定高效。
总结: 本地AI体验的新高度
▲GTi15 Ultra 凭借硬件算力的跃升与软件生态的深度适配,在本地AI应用、生产力赋能、语音交互及网络协同四大核心维度实现突破,能够为个人与专业场景提供高效灵活的智能解决方案。
GTi15 Ultra 通过“算力 - 模型 - 场景”的深度融合,不仅让普通用户享受到直观易用的本地AI功能,也为专业人士解决了算力受限、响应延迟和多端协作的痛点。随着软件生态持续升级与应用场景不断拓展,GTi15 Ultra正将终端AI体验推向新的高度,成为引领设备智能化转型的关键推动力,助力本地AI真正进入“好用、易用”的新阶段。
悦来网提示:文章来自网络,不代表本站观点。